 xxl
xxlCMU 15445 Project 1
Foreword
从 Project-0 到 Project-1 中间摆了好几天. 出完分发现保外有点希望又开始白兰地了.
环境配置上彻底换成了 CMake-tools 和 clang-14, 中间配置时遇到了一些问题, 例如找不到 dwarf_producer_init_c 导致编译直接失败的问题. 后面发现是因为使用了 ninja, 不支持或者过于严格冲突了, 后面将设置改为 Unix Makefiles 之后就好了.
|
|
然后先说优化结果, LeaderBoard 排名第 8 (2024/01/26), 优化结果如下:
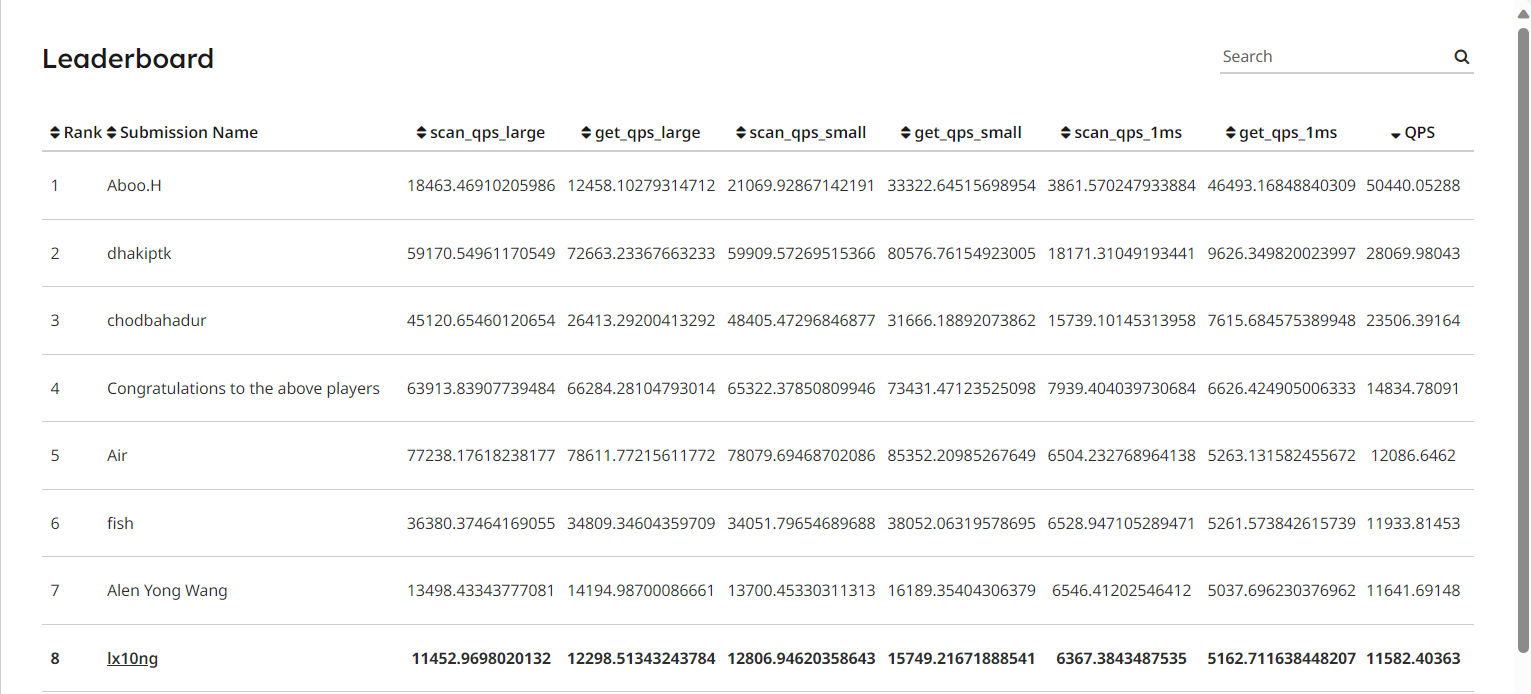
figure-1 LeaderBoard
给前面几位神仙磕一个 orz, 不过我有合理理由怀疑前面也有 hack 的. 有的数据还是太吓人了.
这个 LeaderBoard 是有漏洞可以绕过的, 如果 just hack for fun, 可以直接刷榜到第一. 当然如果这样已经失去其原本的意义了. 所以截个图图一乐, 后面还是 active 正常的优化方式得到的结果了.
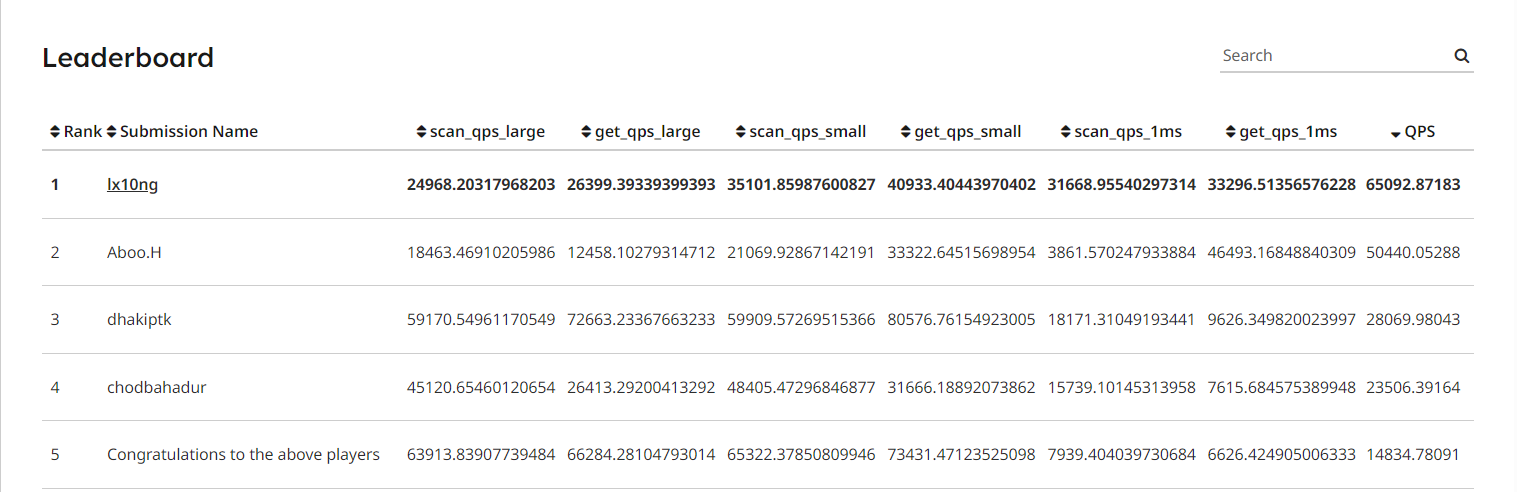
figure-2 hack_for_fun
基于课程要求, 本文并不包含代码实现, 也不会公开仓库. 不过欢迎读者找我交流. lx10ng@qq.com
Task #1 - LRU-K Replacement Policy
RecordAccess
使用两个队列分别记录以 K 频次划分的访问记录. 每次访问时, 结点记录当前的时间序列, history_count_ 加一. 然后分别处理:
- 如果小于 K, 那么不作更改, 因为小于 K 频次时 FIFO.
- 如果等于 K, 那么将结点从
history_list_中移动到lru_list_中. - 如果大于 K, 那么逐出结点记录的最早访问记录, 然后再将该结点在
lru_list_中按照时间序列插入到合适的位置.
Evict
按序遍历两个队列, 逐出第一个可驱逐的结点即可.
后面几个函数按照要求写差不多等于翻译了. 这里的并行比较简单, 直接一把大锁给每个函数锁住就行. 主要瓶颈也不在这里, 所以后面也没有对这里做什么优化.
Task #2 - Disk Scheduler
这一部分是 2023-fall 新加的实现, 为后面的优化作了很大的提示和准备了. 就是将 IO 操作独立出去, 通过独立的工作线程不断地从任务队列中取出任务并执行. 完成后设置回调, 这样可以将 IO 操作和计算操作分离, 从而提高 CPU 的利用率. 用空任务来结束线程的循环, 实现析构.
同时这一部分是不需要加锁的, 因为取任务的函数已经做到线程安全了, 对同一个页面的 IO 操作的锁通过后面的 BufferPoolManager 来实现.
Task #3 - Buffer Pool Manager
好, 现在到 Project 1 的核心部分了. Buffer Pool 需要管理内存和磁盘的页面交换实现类似于虚拟内存的功能.
NewPage
调用时先从 free_list_ 查看有无空闲的 frame. 如果没有再检查 lruk, 置换出一个页面. 如果置换成功修改对应的元数据.
FetchPage
先检查 page_table 查看该页是否在内存中, 是则直接返回. 否则需要一个空闲页框, 获取方法同上, 然后修改元数据, 将数据从磁盘读回内存.
UnpinPage
对页面操作时会对页面 PIN 住, 用于防止操作时被换出. 操作结束后需要 Unpin 解锁, 同时记录本次操作有无改变页面内容, 因此需要对 is_dirty 进行 |= 操作.
FlushPage/FlushAllPages
对 Page 进行检查是否为脏页面, 执行写回操作.
DeletePage
就检查然后执行元数据清除操作, 最后将删除后空出来的页框加入到 free_list_.
AllocatePage
需要加一个针对该元数据的锁, 用于保持并发和互斥.
Leaderboard Task
Two-phase locking
最有趣的部分来了.首先我们目前已经拿到了初始的 100 分, 但是还是完全串行的操作, 整个 buffer pool 通过一把大锁来控制并发, 导致大部分 CPU 完全浪费在锁的等待上. 我们完全可以细化锁的粒度, 来实现不同页面并行操作, 只在对于公共数据, 例如 page_table_ free_list_ 时通过锁来互斥.
由于我们已经将 IO 操作独立线程处理了, 所以显然, 目前瓶颈在于一个页面处理 IO 时, 其余页面被共有的大锁锁住了.所以目前主要任务是将 buffer pool 的各个函数对不同的 page_id_ 能够实现并行. 那么我们便需要以下几个锁
|
|
但是初步加锁时, 我想当然地使用类似这样的锁最小粒度地包括了各个元数据操作. 结果可想而知, 自然不是死锁就是不一致性问题.
|
|
在这里卡了许久之后, 我才明白我可能缺少对锁的认识. 捡起大二上的数据库课本看了眼, 才发现『两段锁协议』这个名词.(考完试就忘, 大学生是这样的)
By the 2PL protocol, locks are applied and removed in two phases:
- Expanding phase: locks are acquired and no locks are released.
- Shrinking phase: locks are released and no locks are acquired.
有了这个理论加持, 锁的安排就方便多了. 我们首先对每一个函数列出需要的锁, 指定需求获取顺序, 由于两段锁的释放必须在所有锁获取之后, 因此所有锁的获取顺序必须确定, 否则可能导致死锁. 在我的实现中,顺序是:
|
|
那么有了两段锁协议导致锁的获取提前了, 那效率不是降低了很多吗?
别急, 基于这个方式的锁的获取下, 我们还可以做的优化还有很多.
首先对于 page_table_ 我们并非所有的操作都是互斥的, 因此我们可以引入读写锁, 在开头查询是否该页是否在内存时只需要获取 shared_lock 即可, 后面需要更改时, 再在受保护的情况下对锁进行升级. 这样可以大幅度提高访问内存中页面的并发性.
虽然 c++ 并没有提供标准的锁的升级, 导致这里看起来是不安全的, 但是需要对 page_table_ 先读再写的操作的函数只有一个 FetchPage.而在这个函数中, 我们又需要对 free_list_ 进行操作, 尽管操作在最后, 我们还是为了保持锁的顺序性将其提前到最先获取. 那么这种情况下, 我们读写锁的升级就是在 free_list_mutex_ 的保护下进行的了.
说了这么多不还是要先获取一个锁来保护吗? 那不是相当于没优化?
别急, 虽然锁的获取上我们可做的工作不多了, 但是我们可以调整后面临界区的操作, 使得锁的释放操作提前.
还是拿 FetchPage 举例子, 我们可以在拿到 guard_page 也就是最后一个锁之后, 先进行另外两个锁的临界操作, 将他们提前释放, 然后再进行较为耗时的磁盘 IO 等待, 从而提高并行效率.
所以整体地思想就是, 先按照两段锁协议对锁进行排序, 实现线程安全地操作. 然后在有锁保护的情况下可以加入读写锁的升级. 最后对各个临界操作进行前后的调整, 使得最后一个锁的获取和其余锁的释放尽量提前, 将耗时操作后移.
按照这个思路, 到目前为止, 前四项无延迟的 qps 基本可以达到接近 4w, 已经可以杀到前四项十名左右了. 这里大致是优化完了, 但是为什么 qps_1ms 的数字还是只有两三百呢?
Mutiple Disk thread
我们使用 perf 查看一下究竟卡在了什么地方
|
|
将 profile.linux-perf.txt 用 speedscope 打开.

figure-3 speedscope1
可以发现, 主要的时间占用是被 disk_manage_ 给占据住了, 只有一个线程在后台处理任务是跟不上速度的, 于是我们决定多加几个 WorkThreads. 在添加了磁盘线程之后, 我们可以看到, 原本的瓶颈已经大致解决了. (不过肉眼可见地还有很多可以优化的地方
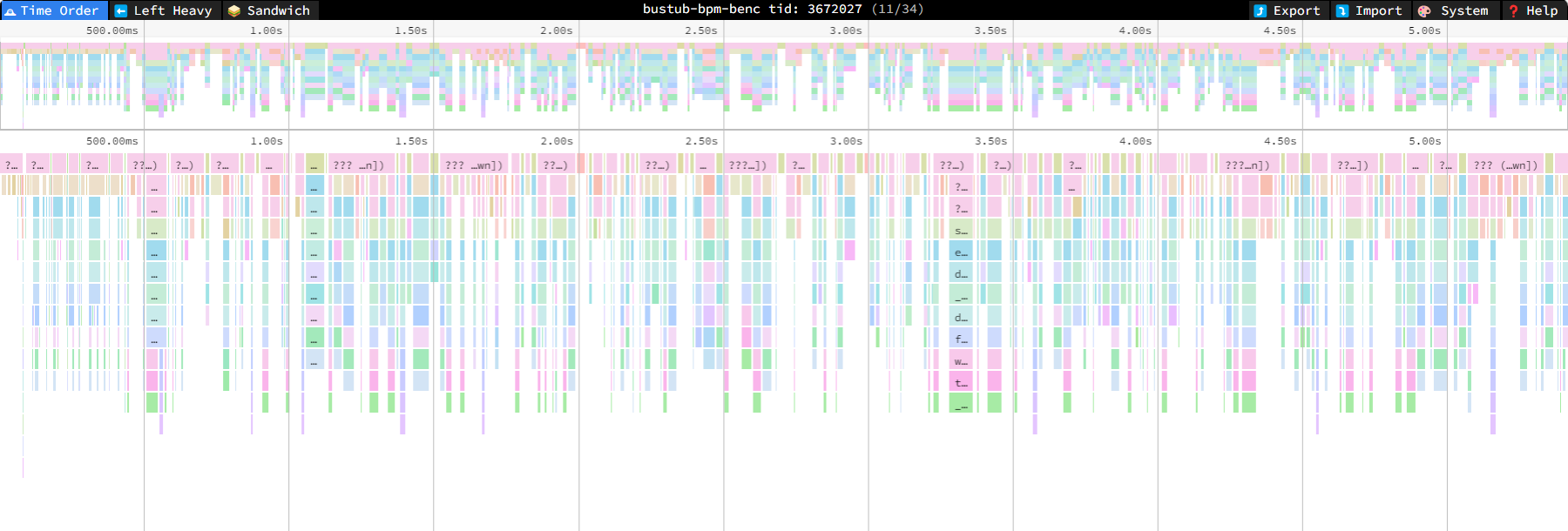
figure-4 speedscope2
因此我们采用线程池的方式, 建立若干个工作线程, 检测到任务时分派给他们, 从而实现线程消耗和任务等待的平衡.至于后台线程数量什么时候最佳, 如何处理多个线程的析构问题, 就交给读者自行处理啦.
最后欣赏一下理论上的调用图的优雅吧 (just hack for fun)
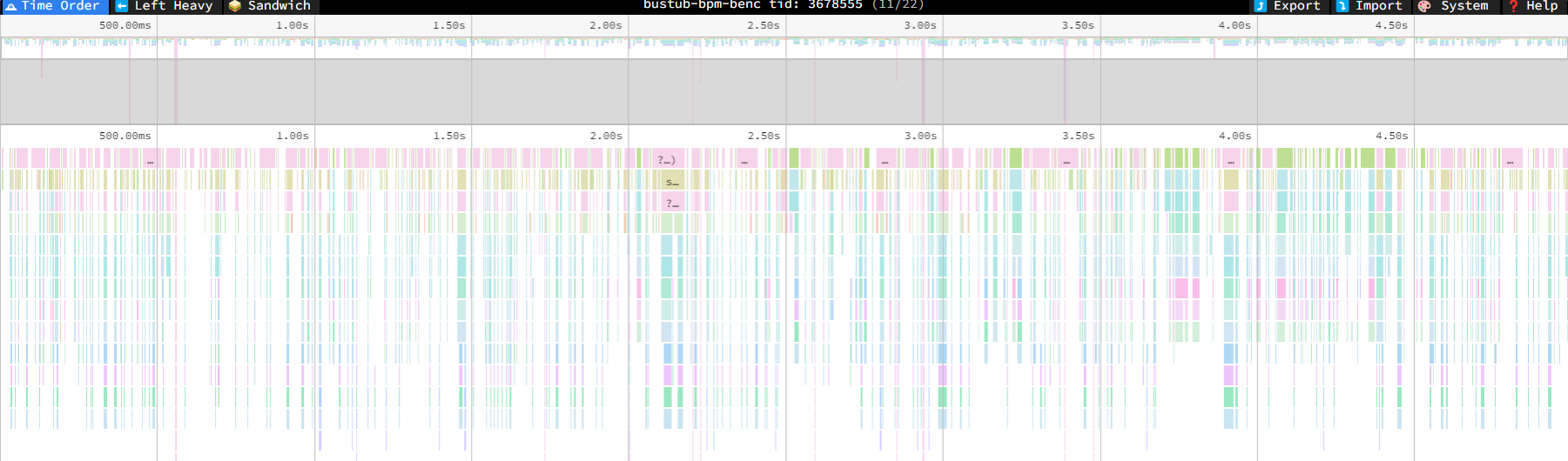
figure-5 speedscope3
Potentially useful but unimplemented ideas
-
对于没有磁盘延时和有延时的任务来说, 所需要的后台
WorkThreads数量是不同的, 同时对于同一个场景下, IO数量的任务也可能随着时间变化, 可能一会是 CPU 密集型, 一会是 IO 密集型. 对于这种情况, 固定容量的线程池就无法较好地胜任了, 我们需要新加入一个线程用于检测request_queue_和workingthread的相对程度, 来动态调节线程池的容量, 使用类似于已经学过的 TCP 控制流量的方式来间接控制. -
LRU-K 的实现效率还较低, 复杂度最差为 $\text{O}(n)$, 理论上可以通过引入树型结构达到 $\text{O}(\log{n})$. 同时这里也还是一把大锁, 可以做适当的并行优化.
-
我的实现中并未对于
AccessType进行特别处理, 理论上Scan线程实际上是污染了LookUp线程的访问频次的.
不过由于已经在这个 Project 上花费了太多的时间, 先接着推整个 Project 的进度了, 以上的有空再修改吧.
相信后人的智慧
Conclusion
非常有趣的一次实验, 从初步接触 modern c++17 的懵懂, 到后面通过已学知识对并发不断地优化刷榜, 整个过程可太有收获了.
该部分并行优化实现时参考了一部分散落的叶子大佬的思路 CMU 15-445 2023 P1 优化攻略.